Reading Time:
10 minutes
Artificial Intelligence has become “mainstream” after ChatGPT was released in November 2022.
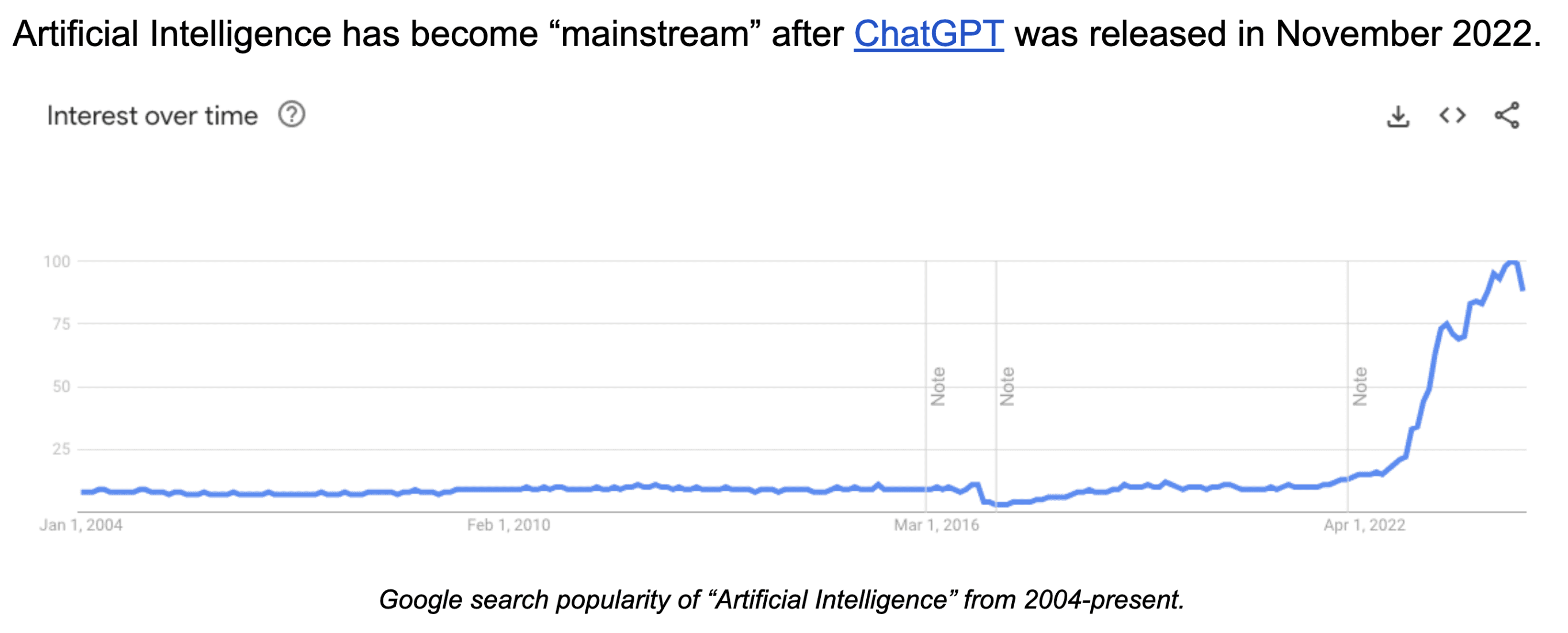
ChatGPT set the record for fastest-growing user base of all time, exceeding 100m users in less than two months, and demonstrating to the world that AI can now generate coherent answers and solve problems that previously felt far out of reach.
Expectedly, the AI discourse has become heated and polarized. Commentary ranges from “AGI is around the corner” to “AI is overhyped.” Google employees debate whether AI is “becoming conscious” or just “parroting humans.” Those expecting rapid progress take sides on whether AI will spell humanity’s “doom” or “salvation.” Because opinions diverge so wildly, newcomers to AI often find it difficult to even start to make sense of the discourse.
We believe that three key facts cut through today’s polarized conversation, and make it clear that the modern AI era is concerning:
In Rapid AI progress is driven by resources, not insights, we highlight that modern AI capabilities are driven not by individual research breakthroughs, but by a simple paradigm that scales with more data, compute, and energy, and that the resources to push AI much further are being invested.
In AI is grown, not built, we explain how deep learning, the core method underpinning the last decade of AI progress, leads to AI systems that researchers can neither understand nor fully control.
In The race to AGI is on, and potentially deadly, we argue that the core actors developing AI today are ideologically driven to build AGI, technology that experts warn may lead to extinction.
AI capabilities have dramatically improved in the past three years, crossing crucial thresholds of competence in domains such as coding, verbal communication, abstract reasoning, image recognition and generation, vocal simulation, planning, and autonomous execution and refinement.
The trendlines comparing AI and human test scores show striking progress: AI is now better at image recognition and reading comprehension than most humans, and approaching near-human performance in domains that were thought to be out of reach, such as predictive reasoning, code generation, and math.
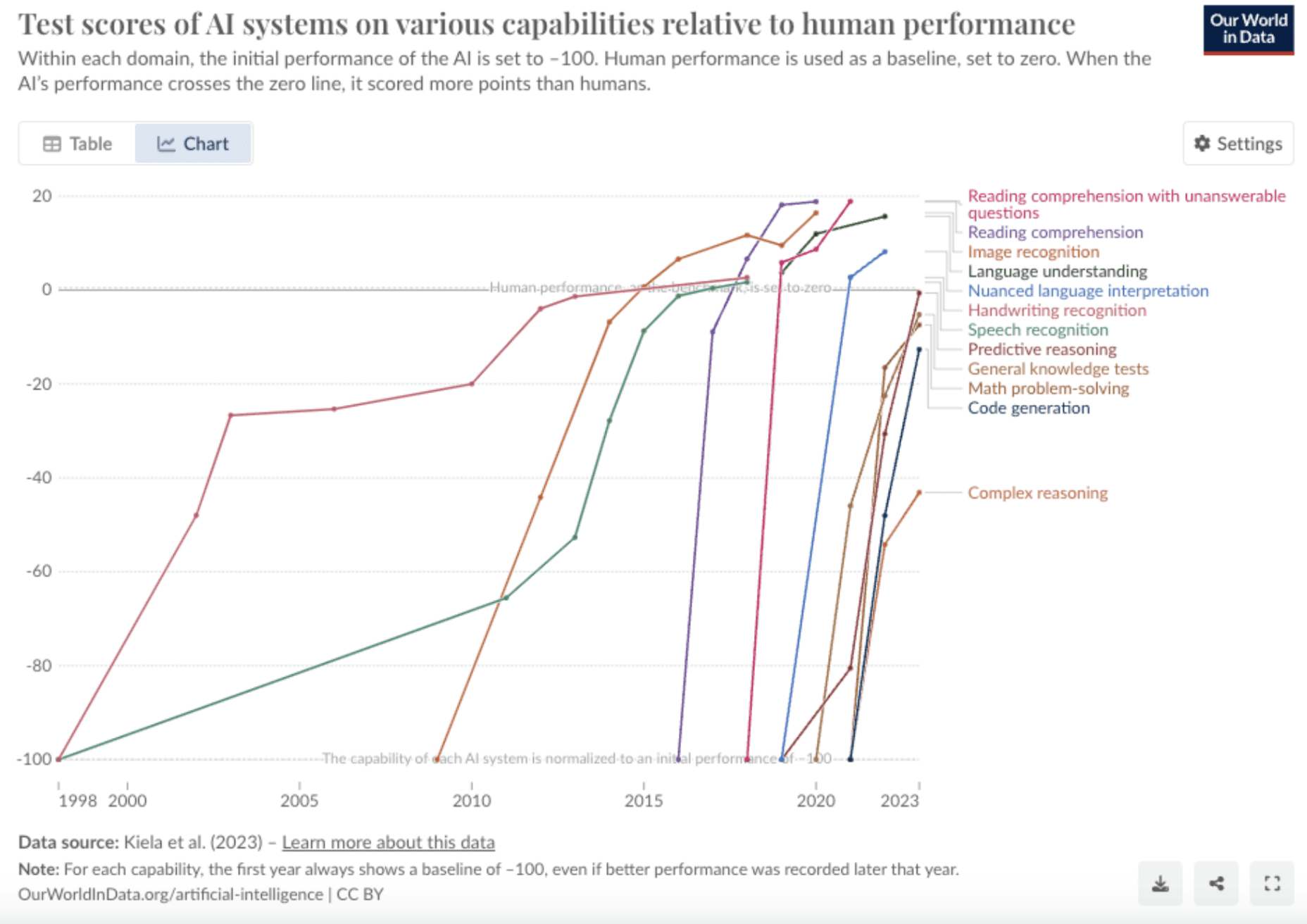
Graphic from OurWorldInData showing AI capabilities improvements over time
Test scores are a contentious predictor of AI's actual capabilities, but businesses are nevertheless adopting AI, suggesting that AI performance is not superficial. Five years ago, few businesses claimed to use AI; today, nearly 65% of all businesses use it to perform some cognitive labor. Perhaps most notably, AI can now code well enough to significantly accelerate the work of even the best human coders — Y Combinator startups use AI to write between 40%-90% of their code, a job that would typically require a three- or four-year STEM degree or equivalent self-education.
This massive jump in capabilities was driven by resources, not insights.
In the last five years alone, the GPT models that underpin OpenAI’s ChatGPT have gone from useless to groundbreaking purely through scaling. When GPT-1 was released in 2018, it could merely write grammatically correct sentences. GPT-2 (2019) could write prose, poetry, and metaphor. GPT-3 (2020) could write stories, with characters that maintain coherence over time. Today, GPT-4 can pass college-level exams on the first try, support complex legal work, and personalize language learning.
This has significant implications for the future of AI progress, because it means that resources are the only obstacle to greater capabilities. Forecasts show that in terms of power, chips, data, and latency, there is ample room to grow, at least until 2030.
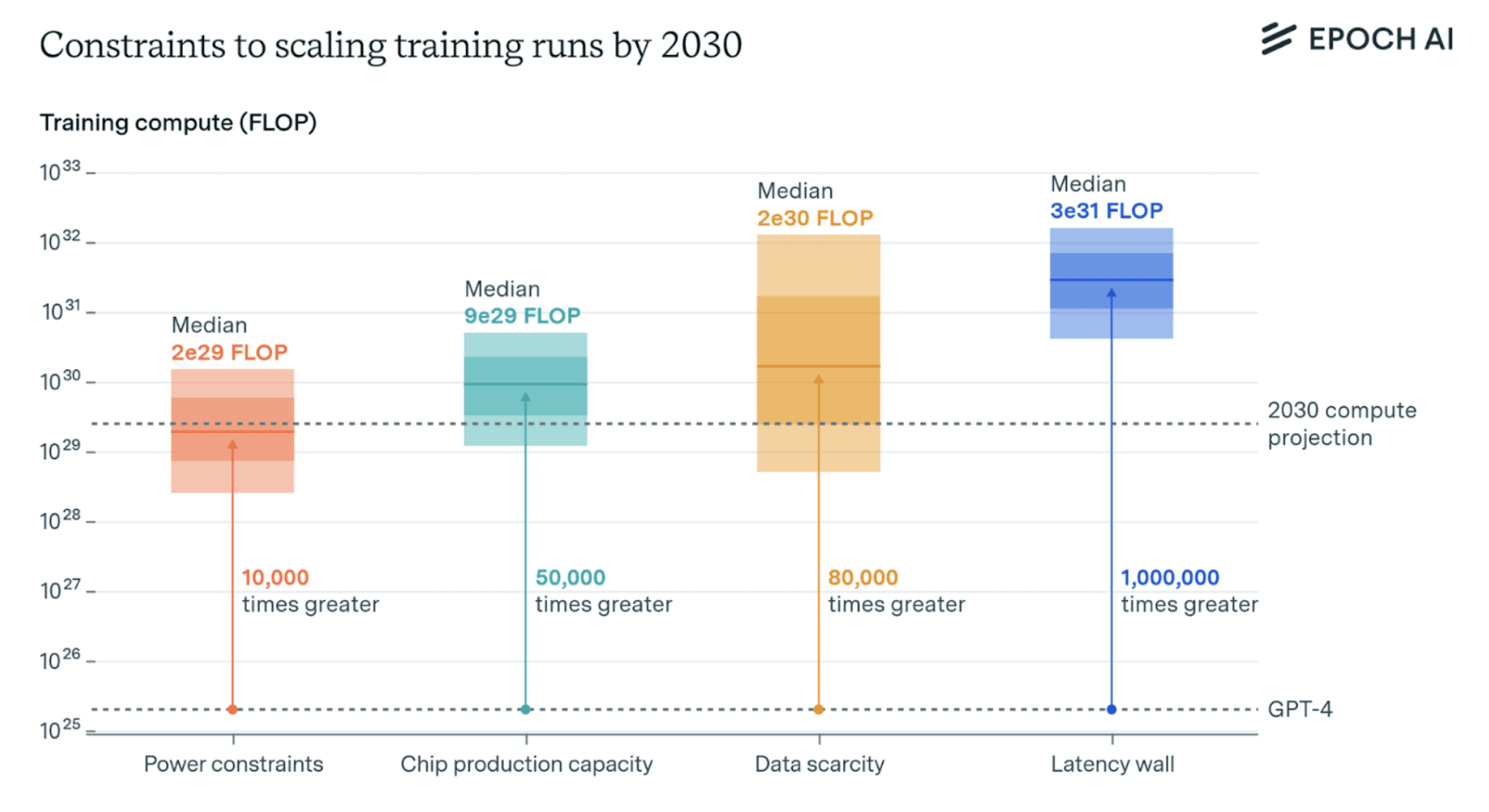
The most likely and proximal blocker is power consumption (data-centers training modern AIs use enormous amounts of electricity, up to the equivalent of the yearly consumption of 1000 average US households) and chip production capacity (AI relies on graphic processing units (GPUs), which are specialized circuits that can perform high-speed calculations).
In response, there have been coordinated investments to support AI development. Google, Amazon, and Microsoft are partnering with frontier AI companies to funnel billions of dollars toward scaling, in turn providing them with the necessary compute power; new compute companies are raising billions from private equity. Microsoft and OpenAI are investing $10 billion into renewable energy sources to power them; others are buying up nuclear power.
To avert future chip shortages and supply chain failures, the US government has committed to investing in domestic semiconductor development and embargoed GPUs from being sold to China in a trade war move to keep the US ahead on AI. Incumbent GPU manufacturer Nvidia has shifted its focus to optimizations for AI, making it the highest market-cap company in the world by November 2024, at more than $3 trillion valuation. xAI already has a 100,000 GPU cluster online, and Meta claims to be training their latest models on an even bigger one. OpenAI is raising billions to support continued development and fund compute requirements.
What this all means is that the world is investing in an approach to AI that assumes the only requirement to further AI progress is more resources (chips, power, data…). If this thesis holds true, then we should expect that AI in five years will be orders-of-magnitude more powerful than today’s AI, just as GPT’s capabilities improved from barely coherent to college-level performance simply due to scale.
Traditional software is coded line-by-line by engineers, by who need to understand broadly how the program works.
In contrast, modern AI models are developed using deep learning, a technique that feeds neural networks troves of data to train them to recognize patterns and make predictions. A neural network is essentially a large graph of billions of numbers that encodes a program. Human engineers are completely unable to determine all of these numbers by hand themselves, so instead they automate the process.
The numbers are initially chosen at random. Then some piece of data is fed to the neural network, and its answer is checked against the correct one. If the answer was incorrect, an automated program twiddles with the numbers to nudge the output of the neural network closer to the correct answer. This is repeated trillions of times using data that often includes significant portions of the internet and public libraries until the neural network is very good at producing correct answers.
Although this sounds straightforward, the resulting AIs are incredibly complex, and able to do things far beyond what they were trained to do. As an important example, large language models (LLMs) such as OpenAI’s GPT4 and Anthropic’s Claude are trained only to predict the next few characters in text, over a huge portion of the internet and books available. Yet from that apparently simple prediction task emerged wild capabilities, such as being able to tell jokes, analyze complex legal documents, and write software.
These capabilities are “grown” in the sense that they are not built deliberately into the model by programmers, but rather emerge from patterns in large amounts of data. This presents two significant consequences:
Modern AI systems have been referred to as “black boxes.” Unlike inspecting ordinary code, inspecting a neural network offers little insight into how it works, and the graphs of billions of numbers are largely inscrutable to humans. The field of AI interpretability has emerged in an attempt to understand AI models and explain their behavior, much like how neuroscience studies the brain. But despite some encouraging progress, interpretability is unable to make sense even of large models from a few years ago like GPT2, and nowhere near completely understanding current LLMs such as GPT4 and Claude.
Not only are researchers and engineers unable to understand how grown AI systems work, but they are also unable to predict what they will be able to do before they are trained.
Many experts have placed bets on AI’s limitations, only to be proven wrong when the next generation of model is released. Bryan Caplan, an economist known for placing winning bets, wagered that an AI system would not be able to score an “A” (the best possible grade) on 5 out of 6 of his exams by January 2029. He based his prediction on the fact that the original ChatGPT release scored a “D” in 2023; just a few months later, GPT-4 received the 4th highest grade in the class.
This is just one of multiple such mispredictions:
Francois Chollet, an AI researcher and author of a machine learning textbook, released a benchmark that many thought would be impossible for an LLM to solve, only for an LLM to achieve a score comparable to human performance just days later.
Yann LeCun, one of the three “godfathers of AI,” predicted that LLMs would not be capable of spatial reasoning. He was proven wrong within a year.
AI Safety pioneers Paul Christiano and Eliezer Yudkowsky bet that there was only an 8%-16% chance that an AI system would score gold on the International Math Olympiad by the end of 2025, but in July 2024, DeepMind’s AI system scored silver, challenging this forecast and shocking prediction markets.
A group of professional forecasters hired by ML expert Jacob Steinhardt predicted in 2021 that a year later, the best score on the MATH dataset would be 12.7%; the actual result was 50.3%. OpenAI’s recently released o1 model scored 94.8%.
All of this leads to AI research where researchers assess the capabilities of AI models after they are trained, using benchmarks and hiring engineers to red-team the models. The outcomes can be concerning: a red-team testing GPT-4 found that it is capable of hiring a human to help it solve a CAPTCHA, a capability that was not tested for during training. Or during Anthropic’s training of Claude 3, the model seemed to exhibit awareness that it was being tested by researchers, something that the researcher had “never seen before from an LLM.”
What makes the situation harder to assess is that after an AI is released, more of its impressive capabilities get revealed by scaffolding techniques that extend AI capabilities even further; this means that the initial release demonstrates only the lower bound on what the system can do. For example, ChatGPT has learned to play complex open-world video games like Red Dead Redemption 2, which was not an obvious capability even after the initial tests.
All in all, this means that the AIs being created and released are not understandable right now by anyone, not even the companies and researchers working on them. This is because they are grown rather than built. And as AIs grow in power, they will become even more complex, mysterious, and illegible.
The main companies driving AI progress today are racing to build Artificial General Intelligence (AGI), AI systems as smart as humans. These companies are all using the same methods discussed above: scaling up deep learning and investing billions of dollars into private data centers and large training runs.
DeepMind, founded in 2010, was the first company to try to build general-purpose AI. Google acquired DeepMind in 2014, and today the Google DeepMind team builds next generation AI systems, acknowledging that “AI — and ultimately artificial general intelligence — has the potential to drive one of the greatest transformations in history.”
OpenAI, creator of ChatGPT, has been pursuing AGI since its inception. OpenAI was founded in 2015 after a dispute over the future of AGI spurred Elon Musk to launch a competitor to DeepMind. Since then, Microsoft has partnered with and acquired a 49% stake in OpenAI.
Musk eventually left OpenAI, but has once again taken up pursuing AGI with xAI, which has built the powerful LLM Grok. In a Twitter Space, Musk allegedly said xAI’s goal is to build “AGI with the purpose of understanding the universe.”
Anthropic, creator of the top-performing AI Claude, is also publicly racing for AGI. Anthropic was established in 2021 after founder Dario Amodei and OpenAI CEO Sam Altman had a breakdown in trust over the future of AGI. Today Anthropic has a $1-4B partnership with AWS, and while AWS has not made public statements on AGI, they have an internal AGI team and recently bought out the founders of $350M-funded Adept to join it.
Competition to train powerful AI models has mostly consolidated among these actors, although new players are jumping in, like Safe Superintelligence Inc., a new start-up by Ilya Sutskever, ex-Chief Scientist at OpenAI, which raised $1B to explicitly train smarter-than-human AIs.
Nearly every AI application today is downstream of these major companies. Foundation models are so named for a reason: they form the foundation for other AI applications. This means that the core risks inherent to these models, such as the fact that researchers do not understand how they work, apply to every AI application that uses them.
As these models become ever more powerful, and orders of magnitude more complex with scale, older generations can be replaced by new and improved systems, meaning that the entire AI industry (and the open-weight ecosystem) becomes increasingly powerful and opaque with each release.
We believe that this is a recipe for catastrophe, and we’re not the only ones. After ChatGPT was released in 2023, global conversation on the risks from AI — including extinction — entered the mainstream.
In May 2023, the Center for AI Safety released an open “Statement on AI Risk,”
"Mitigating the risk of extinction from AI should be a global priority alongside other societal-scale risks such as pandemics and nuclear war."
The letter was signed by hundreds of signatories, including the CEOs of OpenAI, DeepMind, and Anthropic, two of the three “godfathers of AI,” weapons experts, politicians, and academics.
A few months before that, a similar open letter was published by the Future of Life Institute, calling for a pause on “Giant AI Experiments,” a 6-month ban on training AI models more powerful than GPT-4. It has garnered over 33,000 signatures, including Elon Musk’s.
In June 2023, a survey conducted at the Yale CEO Summit found that 42% of CEOs said that AI has the potential to destroy humanity in 5-10 years.
In November 2023, at the first global summit on AI, a consortium of world leaders from the USA, China, EU, and other global powers signed the Bletchley Declaration, which acknowledges the “potential for serious, even catastrophic, harm, either deliberate or unintentional, stemming from the most significant capabilities of these AI models.” Following the summit, the UK, US, Japan, France, Germany, Italy, Singapore, South Korea, Australia, Canada, and the European Union have agreed to establish AI Safety Institutes with a mandate to better understand and mitigate risks from frontier AI.
Why are AI experts, CEOs, and world leaders concerned that AI is an existential threat?
In short, extrapolating the trends of AI progress into the near future paints a grim picture: humanity has unlocked the ability to build powerful AI systems without fundamentally understanding them, and we are poised to enter a future with more powerful and dangerous technology that is less and less under our control.
If this technology is able to meet, and eventually exceed, the capabilities of a human, then we may face a world where we are powerless to control the very AI we have created.
This document presents a worldview that leads us to this claim and unfolds the consequences: humanity may end up extinct unless we intervene today.